
OnlineOCR-sivustolla käytämme kahta vaihtoehtoa optiselle tunnistamiselle. Yksi vaihtoehto on vanha koneoppimisen kehitys, uudempi on tekoälyn avulla.
Koneoppiminen toimii erinomaisesti tavallisen tekstin tunnistamisessa eri kielillä, kuluttaa vähemmän resursseja ja siksi tunnistaminen on käyttäjälle edullisempaa.
Kuinka se tehdään?
Tekoälyn avulla tapahtuvassa tunnistamisessa on valtavat mahdollisuudet, asiakirjan analysointi ja oikea tunnistaminen sekä objektien koostaminen sivulla. Automaattinen tunnistaminen useista kielimuodoista sivulla.
Jotta voit tunnistaa taulukon lähes minkä tahansa vaikeustason - sinun on käytettävä Premium OCR -palvelua sivustolla. Voit siirtyä sivuston etusivulle ja valita Premium OCR -vaihtoehdon.
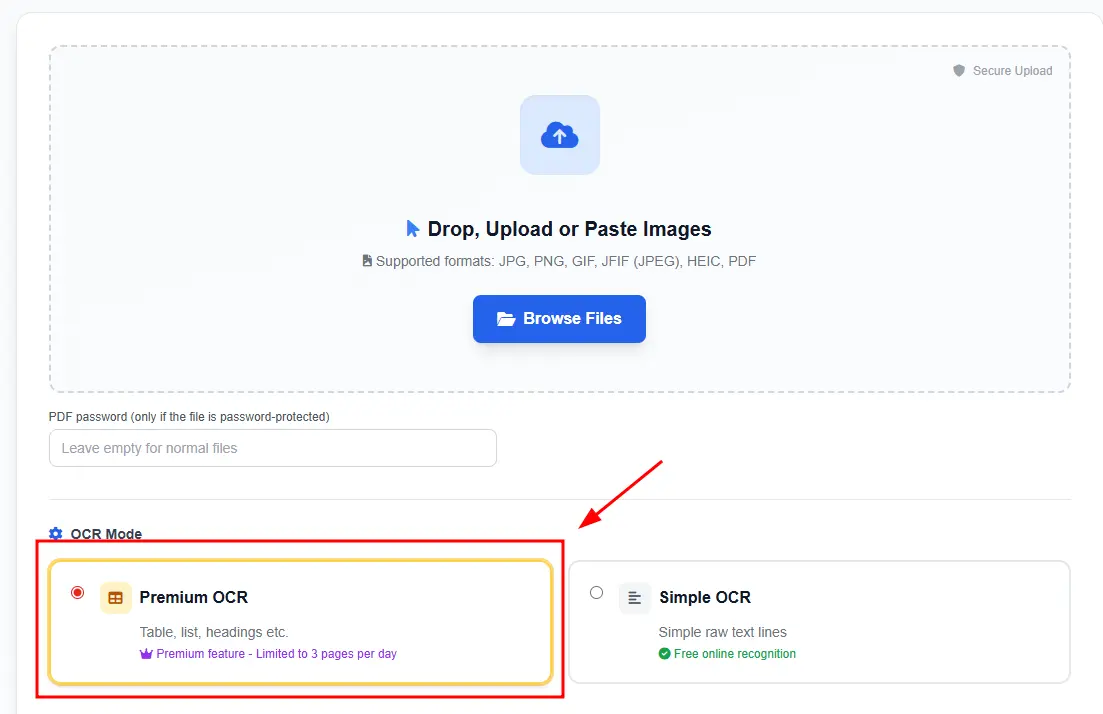 Seuraavaksi seuraa ohjeita ja vinkkejä, ja sen jälkeen saat laadukkaita tunnistustuloksia ja voit valita, miten haluat ladata tiedoston.
Seuraavaksi seuraa ohjeita ja vinkkejä, ja sen jälkeen saat laadukkaita tunnistustuloksia ja voit valita, miten haluat ladata tiedoston.
Toinen vaihtoehto - henkilökohtaisen tilin kautta
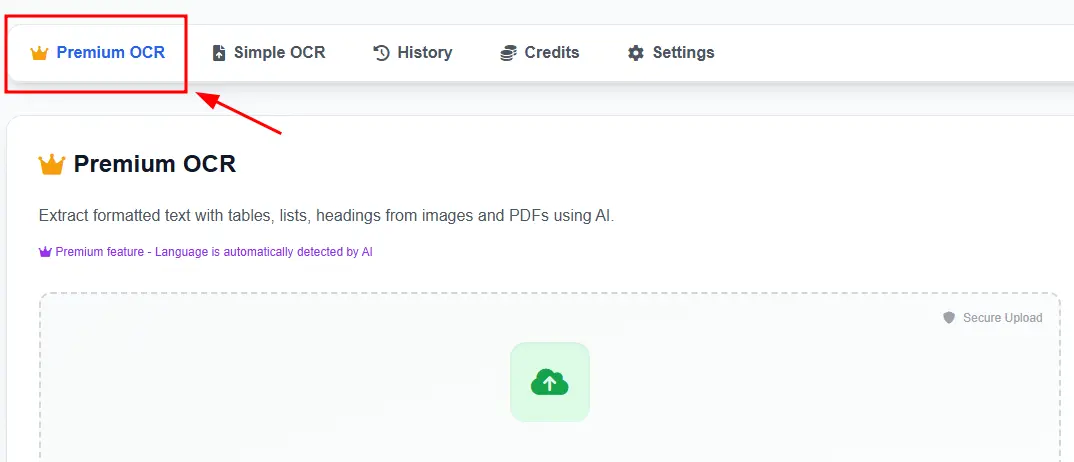
Täällä kaikki on samanlaista kuin etusivulla, mutta henkilökohtaisen tilin lataamisen etu on massalataus, käsittely ja suurten PDF-tiedostojen käsittelyprosessi.