
Na sajtu OnlineOCR koristimo dva tipa optičkog prepoznavanja. Jedan od tipova je stara tehnologija mašinskog prepoznavanja, a novija je uz pomoć veštačke inteligencije.
Mašinsko prepoznavanje odlično se snalazi sa običnim tekstom na različitim jezicima, troši manje resursa i zbog toga će prepoznavanje za korisnika biti jeftinije.
Kako to uraditi?
Prepoznavanje uz pomoć veštačke inteligencije - ovde postoje ogromne mogućnosti prepoznavanja, analiza dokumenta i pravilno prepoznavanje i komponovanje objekata na stranici. Automatsko prepoznavanje nekoliko jezičkih formata na stranici.
Da biste prepoznali tabelu praktično bilo koje složenosti - potrebno je da koristite Premium OCR servis na sajtu. Za to možete otići na glavnu stranicu sajta i u preklopnom meniju izabrati Premium OCR
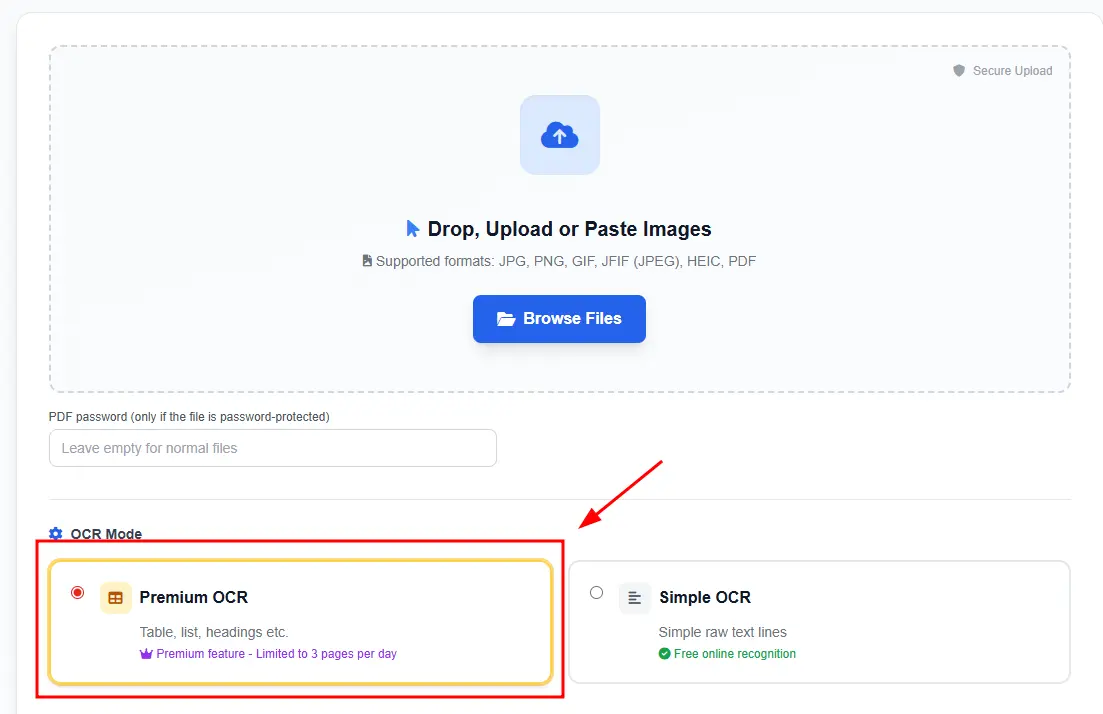 Zatim pratite uputstva i savete i nakon toga ćete imati kvalitetne rezultate prepoznavanja i moći ćete da izaberete način na koji želite da preuzmete fajl.
Zatim pratite uputstva i savete i nakon toga ćete imati kvalitetne rezultate prepoznavanja i moći ćete da izaberete način na koji želite da preuzmete fajl.
Druga opcija - to je preko ličnog naloga
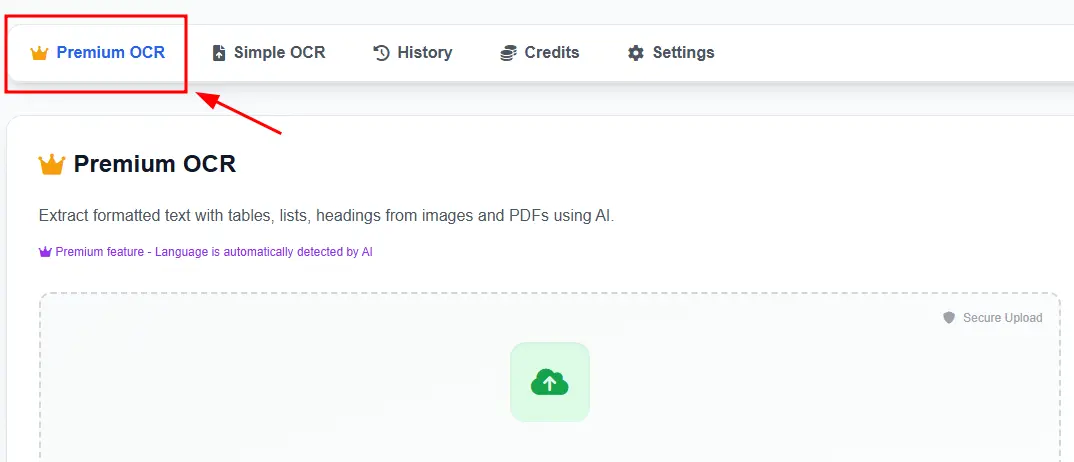
Ovde je sve slično glavnoj stranici, samo je prednost učitavanja u ličnom nalogu - masovno učitavanje, obrada i proces obrade velikih PDF fajlova.